


 お問い合わせ
お問い合わせMemoQの「統計」機能を使って、原稿の文字数のカウントと、原稿の中にどのくらい重複(繰り返し)があるかを確認することができます。
まず、プロジェクトホームから対象文書を選択(クリック)します。
次に、「文書」タブから「統計」を選択します。
ウィンドウが出てくるので、「計算」をクリックします。
すると、統計の結果が出てきます。
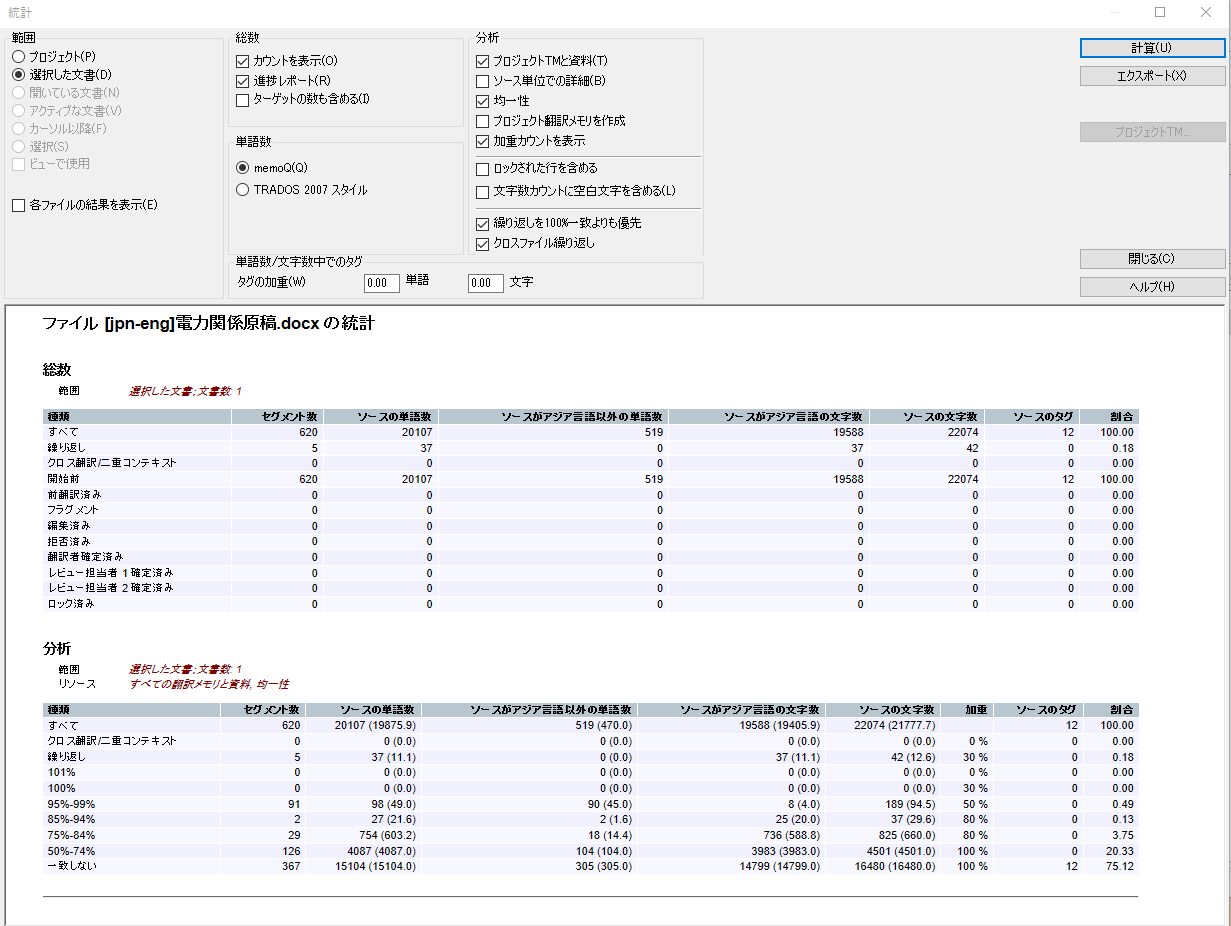
表のうち、原稿の全体の文字数は「総数」の「すべて」⇒「ソースの単語数」の箇所に表示されます。ここでは「20,107」とありますが、これは和文20,107文字という意味です。またこの数字は繰り返し箇所も含みますが、数字など翻訳不要な部分は含まれていないようです。
![]()
繰り返しの文字数は、その下の行「繰り返し」に表示されます。ここでは37文字が重複している文字数になります。

「繰り返し」は同じ原文テキストのセグメントが複数回あることを意味します。
例えばある文章が文書中に3回出てくる場合、1個目は新規翻訳が必要ですが、2個目と3個目には自動的に翻訳が挿入され確定されます。そのため1個目は「一致しない」~101%マッチのいずれかのカテゴリでカウントされますが、2個目、3個目は「繰り返し」として計算されます。
また、その下の「分析」の表で、50%以上一致している箇所がどのくらいあるか、%ごとに結果が表示されます。
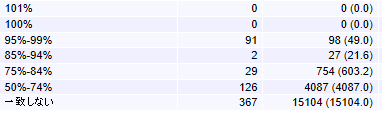
100%マッチは、TMに翻訳する原文と全く同じ原文および翻訳が存在する場合です(完全一致)。しかし、今回の原文の前後の文脈とTMに保存されている文脈が異なる状態です。
101%マッチは、TMに翻訳する原文と全く同じ原文および翻訳が存在し、なおかつ、今回の原文の前後の文脈とTMに保存されている文脈が同じ場合です(コンテキストマッチ)。
このように、MemoQの統計機能を使用して、文字数や繰り返しのカウントを行うことができます。
★その他のMemoQ プロジェクトはこちら★
CATツール:翻訳メモリとは
各画面の説明(DESKTOP版とWEB版)
翻訳プロジェクトの作成方法









")







コメントを残す